Một số notes rút ra sau khi học course Relational Database Administration (DBA) tại Coursera.

Giám sát và tối ưu (monitoring & optimizing) cơ sở dữ liệu là một trong những công việc quan trọng nhất của quản trị viên cơ sở dữ liệu (database admintrators – DBAs).
Monitoring database bao gồm các nhiệm vụ liên quan đến việc theo dõi tình trạng hoạt động hàng ngày của cơ sở dữ liệu nhằm duy trì tính khả dụng và hiệu suất của hệ thống. Nếu việc giám sát không được thực hiện thường xuyên, các issue có thể không được phát hiện sớm và gây nên hậu quả nghiêm trọng cho cơ sở dữ liệu.
Optimizing database bao gồm các nhiệm vụ tối ưu hóa lưu trữ và truy vấn trong cơ sở dữ liệu. Đối với tối ưu hóa lưu trữ, sau một thời gian dài với nhiều thao tác xóa và cập nhật, dữ liệu trong bảng có thể bị phân mảnh và ảnh hưởng nhiều tới hiệu suất truy vấn, khi đó ta cần tối ưu hóa lưu trữ. Đối với tối ưu hóa query, đặc biệt là các query có độ trễ lớn, DBA có thể sử dụng chức năng EXPLAIN để kiểm tra execution plan, xác định các bước tốn thời gian nhất và lên kế hoạch tối ưu.
Monitoring database
Một số nhiệm vụ liên quan đến monitoring database bao gồm:
- Dự đoán các yêu cầu phần cứng trong tương lai dựa trên dữ liệu hiện tại.
- Phân tích hiệu suất của ứng dụng hoặc truy vấn.
- Theo dõi việc sử dụng index.
- Xác định nguyên nhân gốc rễ gây suy giảm hiệu suất hệ thống.
- Tối ưu hóa cơ sở dữ liệu để đạt hiệu suất tốt nhất và đánh giá tác động của việc tối ưu hóa.
Giám sát cơ sở dữ liệu cần mang tính chủ động. DBAs cần xác định các vấn đề của hệ thống trước khi chúng gây ra tác động lớn. Điều này thường được đạt được bằng cách quan sát các số liệu cụ thể từ cơ sở dữ liệu và cảnh báo các bên liên quan nếu phát hiện sự bất thường.
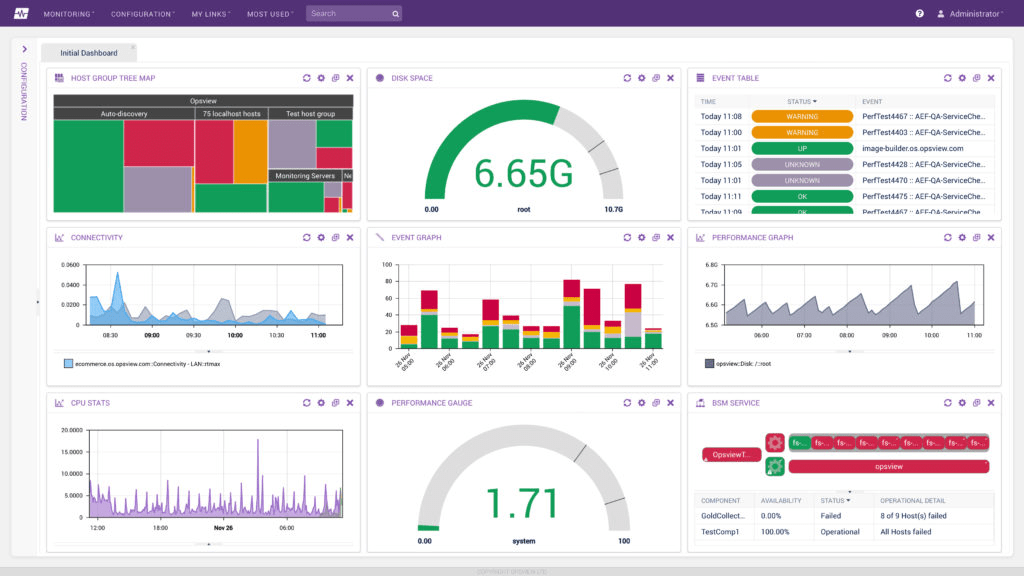
Xác định Baseline hiệu suất
Để xác định hệ thống có hoạt động ở mức tối ưu hay không, ta cần thiết lập một baseline về hiệu suất cơ bản cho hệ thống.
Baseline hiệu suất là các đo đạc hiệu suất chính, được tính toán một cách đều đặn trong khoảng thời gian nhất định. Nó được sử dụng để đối chiếu với tình trạng hiện tại của hệ thống. Nếu hiệu suất hiện tại có độ lệch lớn bất thường so với baseline, cần phân tích và xác định nguyên nhân gây ra sự sai lệch, từ đó xác định các yếu tố cần tối ưu hóa.
Ngoài ra, baseline hiệu suất còn có thể sử dụng để xác định các data pattern, ví dụ khoảng thời gian nhiều truy vấn được thực hiện nhất, trung bình thời gian truy vấn, trung bình thời gian thực hiện sao lưu và khôi phục, …
Metrics

Metrics là các chỉ số hiệu suất chính của cơ sở dữ liệu. Dưới đây là một số metrics quan trọng nhất mà các DBAs cần quan tâm khi monitor database:
- Database throughput: Thông lượng của DB là một trong những chỉ số quan trọng nhất, cho biết tổng công việc đang được thực hiện bởi DB và thường được đo bằng số truy vấn thực hiện mỗi giây.
- Database resource: Giám sát việc sử dụng database resource bằng cách đo lường việc sử dụng CPU, RAM, logs space và storage usage.
- Database availability: Tính khả dụng của DB cho phép ta giám sát DB có hoạt động hay không, có thể được đo bằng tỉ lệ thời gian DB khả dụng.
- Database responsiveness: Cung cấp cho DBA thông tin về thời gian đáp ứng trung bình cho mỗi truy vấn, cho thấy tốc độ họ phản hồi kết quả truy vấn.
- Database contention: Cho biết liệu có sự tranh chấp kết nối giữa các connection hay không thông qua việc đo lường thời gian chờ giữa các connection. Tranh chấp cơ sở dữ liệu xảy ra khi nhiều connection cạnh tranh để truy cập vào cùng một tài nguyên cơ sở dữ liệu cùng lúc.
- Units of work: Theo dõi các transactions tiêu thụ nhiều tài nguyên nhất trên máy chủ cơ sở dữ liệu.
- Most frequent queries: Theo dõi các truy vấn thường xuyên nhận được, bao gồm tần suất và thời gian trung bình để xử lý. Nó có thể giúp DBA tối ưu hóa những truy vấn này để cải tiến hiệu suất.
- Locked objects: Hiển thị thông tin chi tiết về các quy trình bị khóa và quy trình đã chặn chúng. Khóa và chặn ngăn nhiều transactions đồng thời truy cập vào một đối tượng cùng một lúc. Chúng đưa các quy trình cạnh tranh vào trạng thái chờ đến khi đối tượng cạnh tranh được giải phóng và trở lại trạng thái truy cập được.
- Buffer pools: Theo dõi việc sử dụng buffer và table space.
- Top consumers: Hiển thị người sử dụng hàng đầu của tài nguyên hệ thống và có thể giúp DBA lập kế hoạch về phân phối tài nguyên sao cho tối ưu nhất.
Optimizing database
Optimizing storage
Dữ liệu lưu trữ sau một thời gian dài, thực hiện nhiều thao tác delete và update thường sẽ bị phân mảnh lưu trữ trong đĩa vật lý. Khi đó DBAs cần tối ưu hóa lưu trữ nhằm cải thiện hiệu suất truy vấn.
Việc tối ưu hóa lưu trữ thường bao gồm 2 việc, là loại bỏ phân mảnh và sắp xếp lại index. Việc này có thể yêu cầu quyền select, insert hoặc exclusivity lock và ảnh hưởng đến hiệu suất cơ sở dữ liệu tại thời điểm tối ưu.
Tùy từng hệ quản trị cơ sở dữ liệu, ta có các cú pháp tối ưu hóa DB khác nhau. Với MySQL là OPTIMIZE TABLE, PostgreSQL là VACUUM và REINDEX, Db2 là RUNSTATS và REORG.
Optimizing query
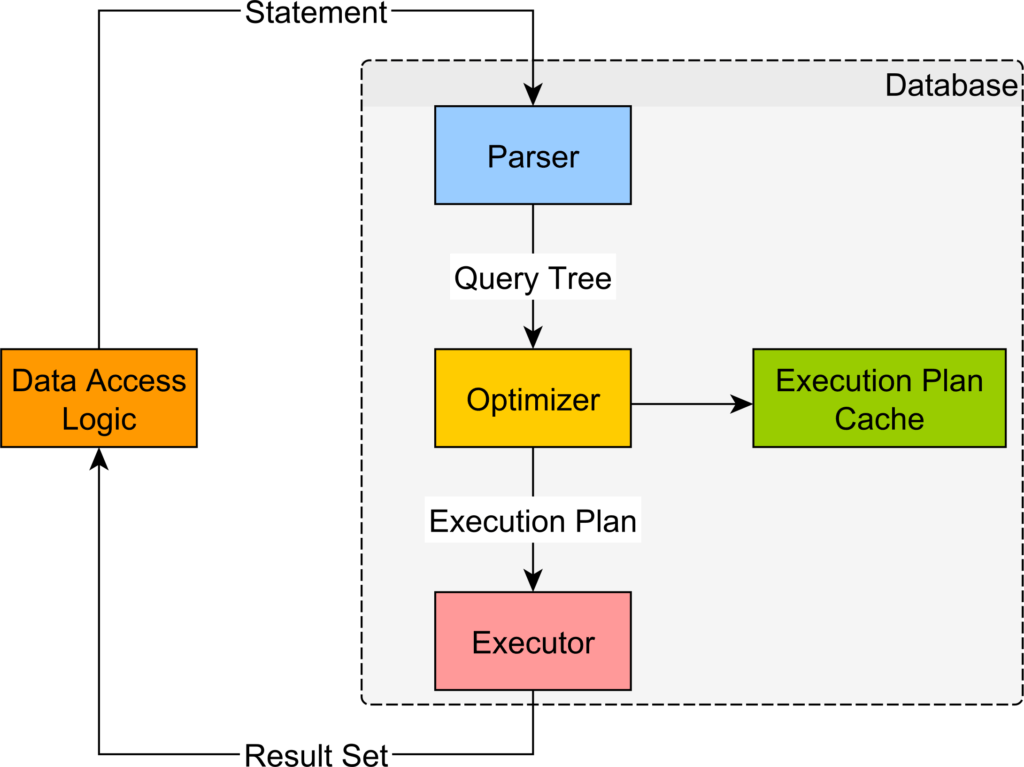
Các hệ quản trị cơ sở dữ liệu cung cấp một công cụ đắc lực hỗ trợ việc tối ưu hóa query là chức năng EXPLAIN, cho phép DBA xem từng bước thực hiện query đã cho và thời gian dự kiến hoàn thành bước đó (execution plan).
Khi đã biết các bước gây mất nhiều thời gian, DBA có thể sử dụng nhiều cách để tăng tốc truy vấn như chỉnh sửa các điều kiện, tạo bảng phụ, …
Indexes
Index là một database object hỗ trợ truy vấn nhanh hơn. Thông thường, index là một bản copy của một hoặc nhiều cột trong table, được lưu trữ sao cho thời gian tìm kiếm là ngắn nhất có thể (BTree or Hash). Mỗi phần tử trong index sẽ link đến 1 hoặc nhiều row trong table và tăng tốc độ truy vấn do index hỗ trợ tìm kiếm nhanh, đồng thời không phải load toàn bộ bảng.

Index nên được thêm vào những cột được truy cập thường xuyên. Mặc dù chỉ mục có thể cải thiện hiệu suất của một số truy vấn, nó cũng có thể làm chậm quá trình insert, update và delete dữ liệu vì cần cập nhật lại index mỗi khi có thay đổi. Do đó, quan trọng là tìm được sự cân bằng giữa số lượng index và tốc độ của các truy vấn.
Ngoài ra, index ít hữu ích hơn khi truy vấn các bảng nhỏ hoặc các bảng lớn mà hầu hết các hàng cần được xem xét. Trong trường hợp hầu hết các hàng cần được xem xét, việc đọc tất cả các hàng sẽ nhanh hơn việc sử dụng index.
Trong database, primary key luôn là index mặc định của 1 bảng, ngoài ra còn có một số dạng index khác:
|
Index |
Mô tả |
|---|---|
| Regular Index | Index có values là non-unique và null-able |
| Primary Index | Index được tự động tạo khi tạo khóa chính, có giá trị là unique và not null-able |
| Unique Index | Index có value và unique và not null-able |
| Full-Text Index | Index được sử dụng để tìm kiếm trong 1 lượng lớn dữ liệu dạng text, chỉ có thể tạo cho cột có type là char, varchar và text |
| Prefix Index | Index sử dụng N ký tự đầu tiên của values, tăng hiệu năng do chỉ phải tìm kiếm ít hơn |
Đối với index có nhiều cột, thứ tự khai báo các cột trong index là rất quan trọng. Dữ liệu trong index luôn được sắp xếp ưu tiên theo thứ tự xuất hiện của cột. Nghĩa là nó sẽ xắp xếp theo cột đầu tiên trước, sau đó mới đến cột tiếp theo.
{kind=link}