Một số notes rút ra sau khi học course Introduction to Data Engineering tại Coursera.
Dữ liệu gốc cần trải qua một loạt các biến đổi (transformations) và làm sạch (cleaning) để sẵn sàng cho việc phân tích. Data wrangling, còn được gọi là data munging, là quá trình bao gồm khám phá dữ liệu, biến đổi và làm cho dữ liệu sẵn sàng để được phân tích một cách đáng tin cậy và có ý nghĩa.
Transformations
Một số phương thức biến đổi có thể nghĩ đến khi nhận được dữ liệu từ nhiều nguồn khác nhau bao gồm: Structuring, Normalization, Denormalization
Structuring

Structuring bao gồm các hoạt động thay đổi hình thức và cấu trúc dữ liệu. Dữ liệu đầu vào có thể có nhiều định dạng khác nhau. Ví dụ dữ liệu từ cơ sở dữ liệu quan hệ và một số dữ liệu từ các API Web. Để kết hợp chúng, ta cần thay đổi cấu trúc dữ liệu nhận được. Thay đổi này có thể đơn giản như thay đổi thứ tự các trường trong một bản ghi hoặc phức tạp hơn như kết hợp các trường thành cấu trúc mới.
Joins và Unions là những phép biến đổi cấu trúc phổ biến nhất được sử dụng để kết hợp dữ liệu từ một hoặc nhiều bảng.
Normalization
Normalization tập trung vào làm sạch cơ sở dữ liệu khỏi dữ liệu không sử dụng (unused), giảm sự trùng lặp (redundancy) và không nhất quán (inconsistency). Dữ liệu từ các transactional systems – nơi thực hiện nhiều thao tác chèn, cập nhật và xóa liên tục – thường được chuẩn hóa một cách chi tiết.
Denormalization
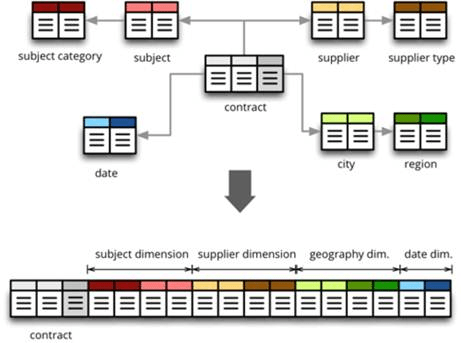
Denormalization được sử dụng để kết hợp dữ liệu từ nhiều bảng vào một bảng duy nhất, làm cho truy vấn thực hiện nhanh hơn. Ví dụ, dữ liệu đã được normalize từ các transactional systems thường được denormalization trước khi chạy các truy vấn báo cáo, phân tích.
Cleaning
Làm sạch dữ liệu (data cleaning) tập trung khắc phục các lỗi trong dữ liệu để tạo ra các phân tích đáng tin cậy và chính xác.
Detech Error Data
Bước đầu tiên trong quy trình làm sạch dữ liệu là phát hiện các vấn đề và lỗi khác nhau mà tập dữ liệu có thể gặp phải. Một số phương pháp thường sử dụng trong giai đoạn này bao gồm:
- Sử dụng scripts hoặc tools để định nghĩa rules và constraints cụ thể, sau đó kiểm tra dữ liệu dựa trên rules và constraints đó.
- Sử dụng các công cụ phân tích dữ liệu (data profiling tools) và trực quan hóa dữ liệu (data visualization tools).

Data Profiling là quá trình khám phá và phân tích dữ liệu để hiểu cấu trúc, nội dung và chất lượng của dữ liệu. Nó giúp xác định các thông tin quan trọng về dữ liệu như kiểu dữ liệu, giá trị duy nhất, giá trị trống, phân phối dữ liệu, độ rộng của các trường, và một số thông tin thống kê khác.
Data profiling có thể được thực hiện bằng cách sử dụng các công cụ và kỹ thuật phân tích dữ liệu như xem xét mẫu dữ liệu, tính toán các thống kê mô tả như mean, median, mode, min, max, và phân phối dữ liệu. Kết quả của quá trình data profiling giúp các nhà phân tích dữ liệu và chuyên gia dữ liệu có cái nhìn tổng quan về dữ liệu, nhận biết các vấn đề chất lượng dữ liệu. Ví dụ, các giá trị blank hoặc null, dữ liệu trùng lặp, hoặc xác định xem giá trị của một trường có nằm trong phạm vi mong đợi không.
Data Visualization là quá trình thống kê và sử dụng các biểu đồ để hỗ trợ nhận ra các giá trị ngoại lệ. Ví dụ, vẽ đồ thị trung bình thu nhập dữ liệu dân số có thể giúp nhận ra các giá trị ngoại lệ (outliers).
Cleaning Techniques
Các kỹ thuật áp dụng để làm sạch dữ liệu sẽ phụ thuộc vào trường hợp sử dụng cũng như loại vấn đề mà dữ liệu gặp phải, một lỗi dữ liệu phổ biến là null data, irrelevant data, outliers, …

- Null data: Các giá trị null có thể xử lý bằng cách loại bỏ các bản ghi có giá trị bị thiếu hoặc tìm cách thu thập thông tin nếu cần thiết. Ngoài ra có thể sử dụng phương pháp imputation, bằng cách tính toán giá trị bị thiếu dựa trên các giá trị thống kê.
- Duplicated data, Irrelevant data: Các giá trị trùng lặp hoặc dư thừa cần bị loại bỏ trước khi đưa vào thống kê. Ví dụ, phân tích dữ liệu về sức khỏe chung của một phân đoạn dân số sẽ không cần thông tin về số điện thoại hay id.
- Data type errors: Việc làm sạch cũng bao gồm chuyển đổi kiểu dữ liệu. Điều này cần thiết để đảm bảo rằng các giá trị trong một trường được lưu trữ dưới dạng kiểu dữ liệu tương ứng của nó. Ví dụ, ngày tháng cần được lưu dưới dạng Date thay vì String.
- Normalization errors: Giá trị dữ liệu đôi khi cần được chuẩn hóa theo quy tắc chung. Ví dụ tất cả đều phải lower case. Các định dạng ngày, tháng cần được đưa về cùng 1 dạng.
- Syntax errors: Các lỗi cú pháp như khoảng trắng ở đầu, cuối string cần được xóa. Lỗi chính tả hoặc viết tắt của địa danh cũng có thể cần được quan tâm.
- Outliers: Dữ liệu cũng có thể chứa các giá trị khác biệt đáng kể so với các quan sát khác trong tập dữ liệu (outliers). Outliers có thể là sai hoặc không sai. Ví dụ, tuổi trong cơ sở dữ liệu của một cử tri có giá trị bằng 5 là dữ liệu không chính xác và cần được sửa chữa. Tuy nhiên, thu nhập một triệu đô la mỗi năm trong khi thu nhập trung bình của tập dữ liệu chỉ là $1000 – $2000/năm là một outliers không sai, tuy nhiên có thể được xem xét loại bỏ tùy vào mục đích thống kê.

{kind=link}